zookeeper集群启动分析
这里从最简单的安装zookeeper的时候,看如何进行选举的,先把最简单的一种梳理好,后面可能涉及到复杂的场景就好整了。
集群环境配置
- 下载最新的release包,把config目录的zoo_sample.cfg修改为zoo.cfg
- 修改配置文件,为了方便源码分析,参数可以循序渐进的加,这里整最基本的参数就OK,配置内容如下:
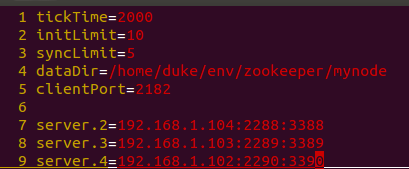
dataDir就为zookeeper内部的数据库路径 - 在dataDir目录新增myid文件,并且里面的值与上面配置文件的server.x参数的数字要一致,如server.2在myid中的值就为2,这个参数很重要,就是server的id,后面选举的时候会用到
- 启动server,./zkServer.sh start,启动前面两台会有java.net.ConnectException: Connection refused: connect,为正常情况,因为配置文件里面配置了3个server,启动的时候会向这些server发送选举请求,没有启动,就连接不上了
- 查看集群状态,使用四字命令stat查看server状态
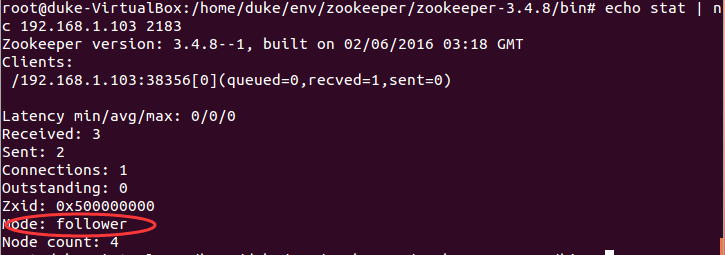
说明集群就成功了。
为了方便debug代码,我把server.4换成了本机的ip地址,各个节点的zoo.cfg也替换掉,在本机执行QuorumPeerMain的main函数即可,如下图:
启动流程
直接参考main函数,由于启动的时候加了zoo.cfg配置文件,所有集群模式的函数runFromConfig,里面设置了QuorumPeer(参与者)一些基本参数,参考代码:
public void runFromConfig(QuorumPeerConfig config) throws IOException {
。。。
ServerCnxnFactory cnxnFactory = ServerCnxnFactory.createFactory();
LOG.debug("初始化NIOServerCnxnFactory配置");
cnxnFactory.configure(config.getClientPortAddress(),
config.getMaxClientCnxns());
quorumPeer = new QuorumPeer();
quorumPeer.setClientPortAddress(config.getClientPortAddress());
//配置文件路径
quorumPeer.setTxnFactory(new FileTxnSnapLog(
new File(config.getDataLogDir()),
new File(config.getDataDir())));
//设置集群的server
LOG.debug("设置选举法人quorumPeers");
quorumPeer.setQuorumPeers(config.getServers());
//设置选举算法类型,默认值为3(FastLeaderElection)
LOG.debug("设置选举算法类型,默认值为3(FastLeaderElection),参考QuorumPeer.createElectionAlgorithm");
quorumPeer.setElectionType(config.getElectionAlg());
quorumPeer.setMyid(config.getServerId());
quorumPeer.setTickTime(config.getTickTime());
quorumPeer.setMinSessionTimeout(config.getMinSessionTimeout());
quorumPeer.setMaxSessionTimeout(config.getMaxSessionTimeout());
quorumPeer.setInitLimit(config.getInitLimit());
quorumPeer.setSyncLimit(config.getSyncLimit());
//选票机制默认为QuorumMaj,N/2
LOG.debug("选票机制默认为QuorumMaj,N/2");
quorumPeer.setQuorumVerifier(config.getQuorumVerifier());
quorumPeer.setCnxnFactory(cnxnFactory);
quorumPeer.setZKDatabase(new ZKDatabase(quorumPeer.getTxnFactory()));
//默认为提议者,LearnerType.PARTICIPANT
LOG.debug("初始化QuorumPeer,学习者类型默认为提案者,LearnerType.PARTICIPANT");
quorumPeer.setLearnerType(config.getPeerType());
quorumPeer.setSyncEnabled(config.getSyncEnabled());
quorumPeer.setQuorumListenOnAllIPs(config.getQuorumListenOnAllIPs());
quorumPeer.start();
quorumPeer.join();
。。。
}画了一个简单的时序图,参考如下: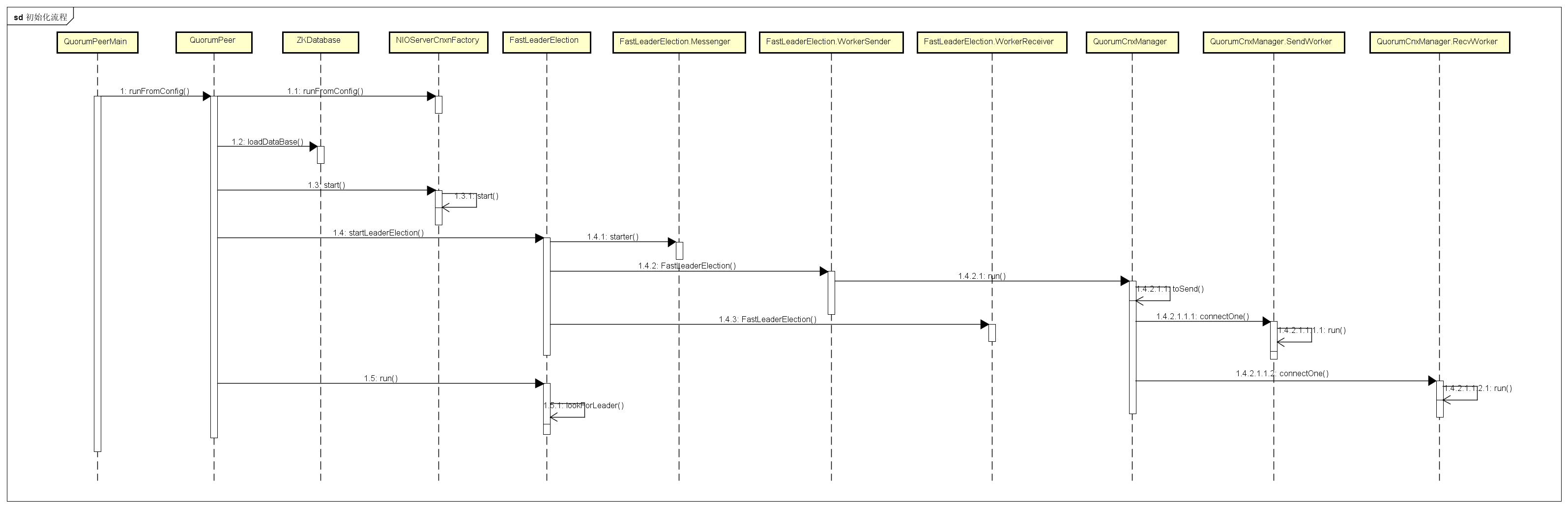
里面的涉及细节,下面再慢慢来分析。
解析配置文件初始化
由QuorumPeerMain的initializeAndRun函数可以看到配置文件zoo.cfg被解析到QuorumPeerConfig对象了,里面集群的server保存到了Map里面,runFromConfig函数将解析出来的值分别设置到QuorumPeer对象。
启动QuorumPeer线程前的准备工作
QuorumPeer的start方法分为3步:
- loadDataBase加载操作文件目录dataDir,刚启动的时候会新建两个重要的文件,acceptedEpoch(接受的选举轮次)、currentEpoch(当前选举轮次)
- 启动nio服务端NIOServerCnxnFactory.start
- 选择选举算法,zookeeper3.4以上版本内部默认只使用FastLeaderElection这个选举算法,创建FastLeaderElection之前,会先实例化QuorumCnxManager,把启动QuorumCnxManager.Listener线程,用于监听请求
下面就对第三步进行详细分析。
通过上面分析可以知道,初始化FastLeaderElection类的时候,就已经把QuorumCnxManager.Listener线程启动了,这个线程就是各个server之间进行通信的入口,参考run方法,部分代码省略:
@Override
public void run() {
。。。
while((!shutdown) && (numRetries < 3)){
try {
ss = new ServerSocket();
ss.setReuseAddress(true);
//是否监听所有ip,默认为false,配置文件可配置
if (self.getQuorumListenOnAllIPs()) {
int port = self.quorumPeers.get(self.getId()).electionAddr.getPort();
addr = new InetSocketAddress(port);
} else {
addr = self.quorumPeers.get(self.getId()).electionAddr;
}
LOG.info("My election bind port: " + addr.toString());
setName(self.quorumPeers.get(self.getId()).electionAddr.toString());
ss.bind(addr);
while (!shutdown) {
//刚启动时会阻塞在这里,收到发送的消息在这里就开始读取
Socket client = ss.accept();
setSockOpts(client);
LOG.info("Received connection request " + client.getRemoteSocketAddress());
receiveConnection(client);
numRetries = 0;
}
} catch (IOException e) {
}
。。。
}从上面的代码可以知道,启动的监听器线程如果没有建立连接,就会一直会阻塞在accept方法。实例化FastLeaderElection的时候,其内部会创建两个守护线程WorkerReceiver、WorkerSender并启动,这两个线程就是各个server之间选举投票发送接收信息的处理器,前期的准备工作就做好了。
执行QuorumPeer线程
从run方法里面可以看到,这个线程会一直运行,直到选举成功,状态修改为非LOOKING状态。接下来选举的过程就交给FastLeaderElection了。参考lookForLeader方法,在开始的时候,会初始化一个逻辑时钟logicalclock,用于同一轮的选举,再通过sendNotifications方法,向发送消息队列写入3个配置好的server信息,如果是自己的serverid就不连接自己的服务器了,直接添加到收到信息队列里面,然后把自己的serverid发送给其他两台服务器。如下图所示,接收到的serverId比自己大的情况: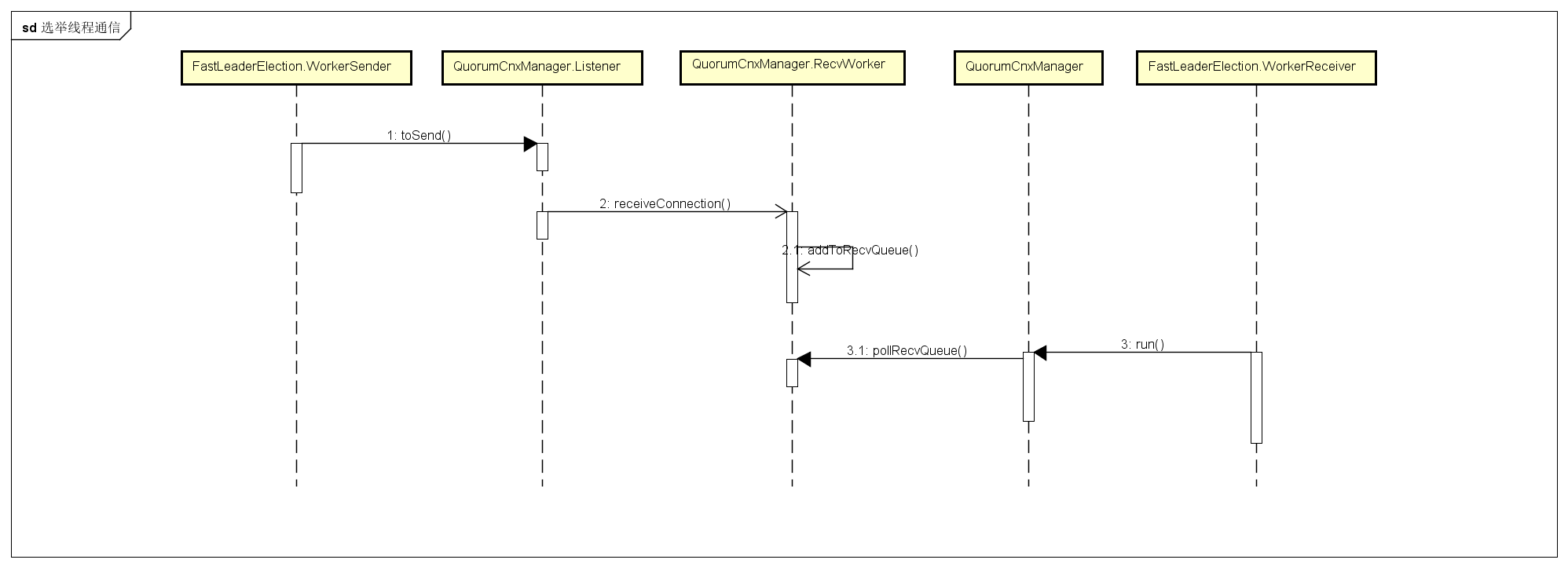
从上面可以看出就是二阶段协议,最终FastLeaderElection就接收到选举通知并存到recvqueue,然后根据这些通知信息进行选举。totalOrderPredicate这个方法就是投票规则,如果同一轮选票,serverId越大或者zxid(事务id)越大,成leader的概率就越大,如(3,5)表示serverId为3,5表示zxid,同一轮选举,zxid越大就投给谁,如下图所示,最后的leader为(1,6):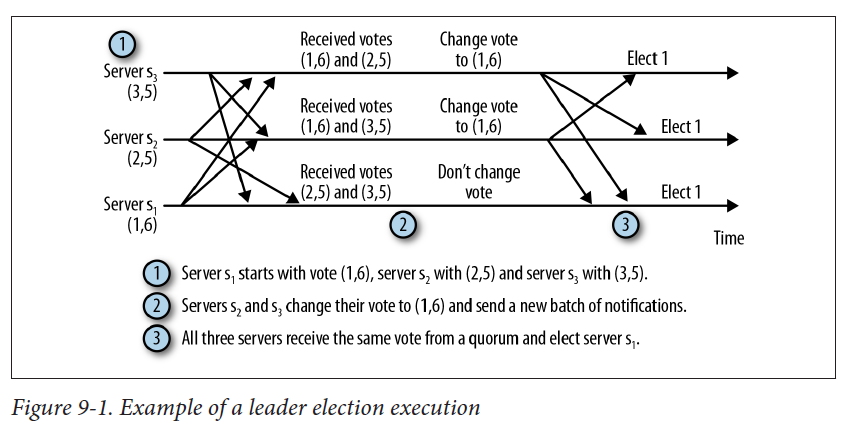
每改变一次投票都会存档(保存到recvset这个集合),最后通过termPredicate方法判断选票节点大于半数就选择修改后的投票里面的server为Leader,如果当前的serverId与修改后的投票里面的serverId相等,那么把QuorumPeer的state修改为LEADING,否则为FOLLOWING。
