mybatis自定义插件实现读写分离
文章目录
mybatis提供了Interceptor接口,这个接口在Executor、ParameterHandler、ResultSetHandler、StatementHandler四个类方法执行的时候进行拦截处理,通过自定义拦截器就可以改变原方法的一些行为,如读写分离、分页查询等,整个过程的执行流程如下图所示:
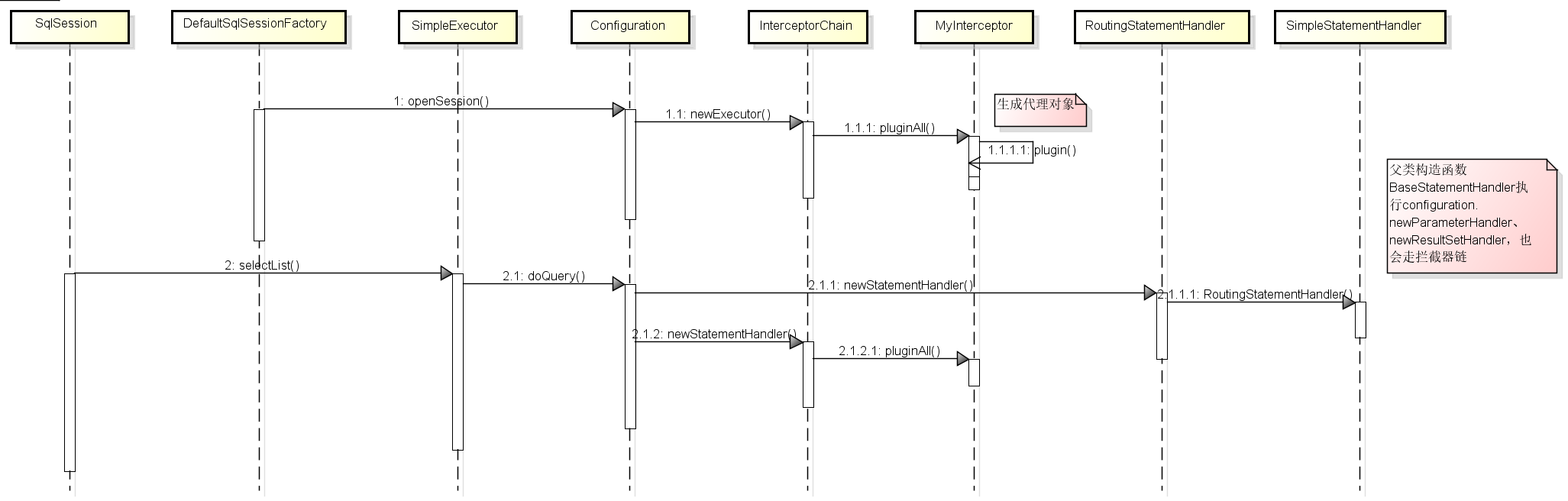
为了设置数据源简单点,自定义的拦截器可以和spring配合使用,实现spring的ApplicationContextAware接口(直接从容器中拿到数据源)就可以了,这里以拦截Executor为例,代码实现如下:
@Intercepts({@Signature(
type= Executor.class,
method = "query",
args = {MappedStatement.class,Object.class, RowBounds.class,ResultHandler.class})})
public class MyInterceptor implements Interceptor, ApplicationContextAware {
public final Logger mylog = Logger.getLogger(MyInterceptor.class);
public ConcurrentHashMap<String, Environment> map = new ConcurrentHashMap<>();
@Override
public Object intercept(Invocation invocation) throws Throwable {
MappedStatement mappedStatement = (MappedStatement) invocation.getArgs()[0];
Configuration configuration = mappedStatement.getConfiguration();
if (map.get("slave") == null) {
Environment defaultEnvironment = configuration.getEnvironment();
//获取从库的数据源
DataSource slaveDatasource = applicationContext.getBean("slaveDatasource", DataSource.class);
//设置从库的环境
Environment.Builder environmentBuilder = new Environment.Builder(defaultEnvironment.getId())
.transactionFactory(defaultEnvironment.getTransactionFactory())
.dataSource(slaveDatasource );
Environment slave = environmentBuilder.build();
map.put("slave", slave);
}
configuration.setEnvironment(map.get("slave"));
return invocation.proceed();
}
@Override
public Object plugin(Object target) {
//将目标对象封装成代理对象
return Plugin.wrap(target, this);
}
@Override
public void setProperties(Properties properties) {
}
public void setApplicationContext(ApplicationContext applicationContext) {
this.applicationContext = applicationContext;
}
}在配置文件中再配置下这个拦截器:
<plugins>
<plugin interceptor="atest.reopen.session.interceptor.MyInterceptor"></plugin>
</plugins>查询的时候使用从库的数据源,这样就动态的实现了数据库的读写分离,这种实现方式看上去拦截粒度比较粗,如果有特殊查询不用从库的,也可以自定义一套规则,把这些特殊的查询排除掉。如果没有特别需求,我感觉这种方式是最方便的了,网上有些从spring aop级别去控制读写分离的,虽然粒度要精细一些,但是像读写分离这种,个人觉得还是越底层实现越好。
